Creating A Responsive & Systematic Approach to Early EdTech Evidence: The LEVI Trialing Hub’s Matrix
By John Whitmer & Alexis Andres, Learning Data Insights

Initial Efforts
To address this challenge, through literature reviews, discussions with LEVI R&D teams and other stakeholders, and a review of results we developed an “evidence matrix” that provides a more robust and comprehensive approach towards understanding LEVI research studies. Our first step was the conceptualization and drafting of the categories. Adapting categories from frameworks involving evidence-based practice (Brighton, Bhandari, Tornetta, & Felson, 2003; Evans, 2003; University of Minnesota, 2023) and the ESSA Tiers of Evidence of the U.S. Department of Education (Regional Education Laboratory – Midwest, 2023), our team came up with a tiered approach to categorizing research. This resulted in three categories: 1) Robust with Randomized/Quasi-Randomized Selections, 2) Moderately Robust With/Without Comparison Groups, and 3) Initial Evidence (descriptive analytics, anecdotal evidence, or simulations).
TABLE: Summary of the LEVI Trialing Matrix
Research Methods: how studies are designed and data collected
| Tier 1 | Tier 2 | Tier 3 | Tier 4 | Tier 5 |
|---|---|---|---|---|
Randomized Experimental Studies (with demographic information) |
Quasi- Experimental Studies |
Analytic studies |
Qualitative or small-scale studies |
Model testing and historical data analysis |
|
Pre-assignment of students to experimental and control groups with demographic information about participants. |
Experiments with control and treatment groups where students are not assigned in advance, usually large scale studies. |
Identify relationships and outcomes in relation to LEVI interventions without experimental design or demographic information. |
Preliminary explorations of product features or interventions. |
Model testing and platform usage analysis to ensure AI approaches are accurate and solutions work as expected. May be based on prior student/tutor data. |
Outcome Variables: what result is measured?
| Type A | Type B | Type C | Type D | Type E |
|---|---|---|---|---|
Externally created and validated assessments |
Modified externally created and validated assessments |
Internally created assessments |
Platform engagement and activity changes |
Model accuracy performance |
|
Includes variables that assess gains in math achievement created by external organizations and validated using robust psychometric approaches. |
Includes subsets or modified items that measures learning gains in mathematics created by external organizations that have been validated. |
Includes variables that assess gains in math achievement using platform-based assessments, analytics, or other internally developed measures. |
Includes variables that assess improvements in student engagement, cognitive skills, critical thinking, or motivation levels. Could also describe changes in non-student behavior (e.g. tutors, teachers). |
Includes variables that assess AI model performance within LEVI platforms, ensuring that applications are accurate. |
Detailed Descriptions of Research Methods & Outcome Variables
This section describes the different categories of research design methods, ordered according to the strength of the analytical method and its capacity to produce the most accurate estimate of the effect of an intervention. The categories below have been adapted from frameworks on the hierarchies of evidence (Brighton, Bhandari, Tornetta, & Felson, 2003; Evans, 2003; University of Minnesota, 2023).
Level 1 Fully Experimental Studies
Studies in this category are intended to demonstrate clear distinctions or to isolate differences that may emerge from the use of a LEVI-funded platform, allowing for delineation from spurious differences or influences from erroneous variables. They feature experimental designs, usually conducted using a Randomized Controlled Trial methodology (Bhide, Shah, & Acharya, 2018). RCTs are regarded as the one of the most reliable methods for evidence collection derived from their capacity to minimize the influences of confounding factors (Sackett, Richardson, Rosenberg, & Haynes, 1997)
Experimental designs isolate intervention effects from other factors both known and unknown that might impact student learning gains by assigning similar groups of students to either an experimental or control condition by using randomization methods. This assignment should be made at the most fine-grained level possible, although in many cases classroom-level assignment is the best approach within the constraints of school requirements and what is feasible to conduct within an actual classroom.
Example: EEDI investigates the impact of EEDI on NWEA scores of low-income students via a year-long RCT. They are assessing gains among low-income students vs non-low-income students and across control and treatment groups. Randomisation will be conducted at the school level and the outcome measure will be attainment defined by progress on NWEA standardized assessments, compared against baseline, midpoint, and post-assessment scores.
Level 2 Quasi-Experimental Studies
Studies in this tier examine whether there is a likely causal relationship between independent and dependent variables. However, compared to the studies in tier 1, these studies often do not randomly assign participants before conducting an experiment, which is often not feasible in naturalistic contexts or in large-scale deployments. Nonetheless, there are many robust methods that include a comparison group and provide significant insights (Cook & Wong, 2008; Kirk, 2009; Rogers, & Revesz, 2019). The combination of scale and naturalistic environments make these studies extremely valuable as a source of insights.
Example: CMU conducted a quasi-experimental study that investigated the use of hybrid human-AI tutoring to enhance learning outcomes, particular among students with disabilities. Analysis involved pretest to posttest comparisons among students with and without disabilities and dosage analysis of PLUS Tutoring using fixed-effects linear models.
Level 3 Analytic Studies
Studies in this category identify relationships between use of LEVI interventions and improvements in math achievement. Unlike Level 1 or Level 2 studies, these studies might not have a control group or a complete understanding of the participant demographics and other characteristics to ensure that intervention effects are not caused by external factors or might have assignment to groups without randomization (Brighton, Bhandari, Tornetta, & Felson, 2003).
Example: RORI is conducting a study to determine math growth over a year using an internal assessment to evaluate the efficacy of using RORI compared to a naturally occuring comparison group. To do so, they collect baseline, midline and endline responses, grades, student responses, compare groups of students using RORI to those not using RORI, and compare student scores to other data collected on students. To the degree possible, researchers investigate the characteristics of each treatment group but cannot control for other differences and may be missing significant information about participants which could influence the results.
Level 4 Qualitative or Small-Scale Studies
Studies in this category include early-stage research initiatives and development. Qualitative and other descriptive methods applied in these studies are essential to offer key insights into how stakeholders interact with and perceive the LEVI interventions, and have the potential to uncover unforeseen factors that may affect the scaling and implementation (Bhide, Shah, & Acharya, 2018). Descriptive studies support exploration in relation to interventions or conditions and provide evidence to contextualize their implementation (Grimes & Schulz, 2002). These studies may be used as a “springboard” into more rigorous research that investigates the impact of these desired interventions on students.
Example: Carnegie Learning conducted a study where they evaluated the usability of MATHstream prototype through 7 tests with participants in grades 6-9. The testing was divided into two parts: the first focused on the platform’s usability on mobile devices, and the second on the usability of the video rewind feature. Each testing session lasted 30 minutes, and a moderator used a test script to guide the participants. They recorded all notes on a Miro board to ensure accurate documentation of the results. While some participants chose not to respond to certain questions, resulting in unusable results from a statistical perspective, the data provides valuable insights into the prototype’s usability.
Level 5 Modeling & Feature Usage Studies
Studies in this category use data from previous studies or simulated data sets that are used to develop statistical or computational models for LEVI platforms. They may also be used to investigate prior platform usage to provide insights about student learning behavior. These studies can also be used to demonstrate the accuracy of predictive models or provide evidence for the development and refinement of features, analytics, and interventions that will be deployed.
Example: CU Boulder investigated how well the Tutor Talk Move model generalized from a different student group to data collected through the Chicago Pilot Study (CPS). This model generates a prediction for every Tutor utterance, using the previous student utterance for context. The fine-tuned Talk Move model achieved significant macro average precision, recall, and F1-scores of 0.80, 0.76, and 0.77 in 10 fold cross validation on 94 Saga sessions. They found that the models generalized well, with only a small reduction in performance, which is a positive result for a model transfer to a new context.
Outcome Variable Type
This section outlines the categories of outcome measures for use with the research plans and completed studies. These categories are arranged to offer a framework that guides the application of each outcome variable, enabling researchers to structure their study results in a way that substantiates evidence of learning gains. Additionally, the categorization maps to a progression from product improvement to increasing learning gains. This progression includes product improvement, increasing learning gains at the student level, and increasing learning gains at the classroom level. This progression is presented below beginning with outcome variables that are most directly connected to learning gains and moving towards those more relevant to product improvement.
Type A Learning Gains - Robust, Externally Validated Measures of Math Learning Gains
These include assessments that have been developed and validated by an external organization with robust testing and validation. These assessments may involve testing of content knowledge beyond mathematics but should provide specific math scores to demonstrate concrete changes for the sample being studied. These include results from a full test administration or subscale that has been validated for stand-alone use.
Examples: NWEA MAP Growth Scores, PISA, State-mandated End-of-Year Exams
Type B Learning Gains - Modified, Externally Validated Measures of Math Learning Gains
These assessments include externally-created and validated measures, but may include less than a complete test administration or validated subscale.
Examples: 7-point Likert scale adapted from previously developed students’ self-efficacy and attitudes (UFlorida)
Type C Learning Gains - Internally Developed Measures of Math Learning Gains
These include assessments developed by teams to provide evidence of math learning gains. The assessments should be rigorous and include pilot testing and other psychometric validation.
Examples: Validated assessments within learning platform
Type D Platform Engagement and Activity Changes
These include metrics collected or qualitative reports from platform activity instrumentation or less robust platform-based assessments (e.g. productive discussion in tutorial sessions). These may include usage logs, interactions, time on platform, and performance on less rigorous measures of learning. Platform analytics include constructs beyond math learning gains, this may include measuring improvements in cognitive skills like problem-solving and critical thinking, changes in engagement and motivation levels, or developments in soft skills such as collaboration and communication.
Examples: Usage Metrics, In-Game Performance, Self-Reports, Lesson Completion Rate, Proxy Measures, Surveys, Qualitative Coding, Interviews
Type E Model Performance
These include performance metrics for statistical, predictive, or computational models that have been integrated into LEVI products. These measures allow teams to evaluate the effectiveness and accuracy of these models and demonstrate improvement over time. These may include the precision, recall, or accuracy of predictive models for learning outcomes, the robustness of statistical models in analyzing educational data, or the efficiency and scalability of computational models in processing large datasets.
Examples: AUC-ROC, Accuracy, Kappa, RMSE, R2
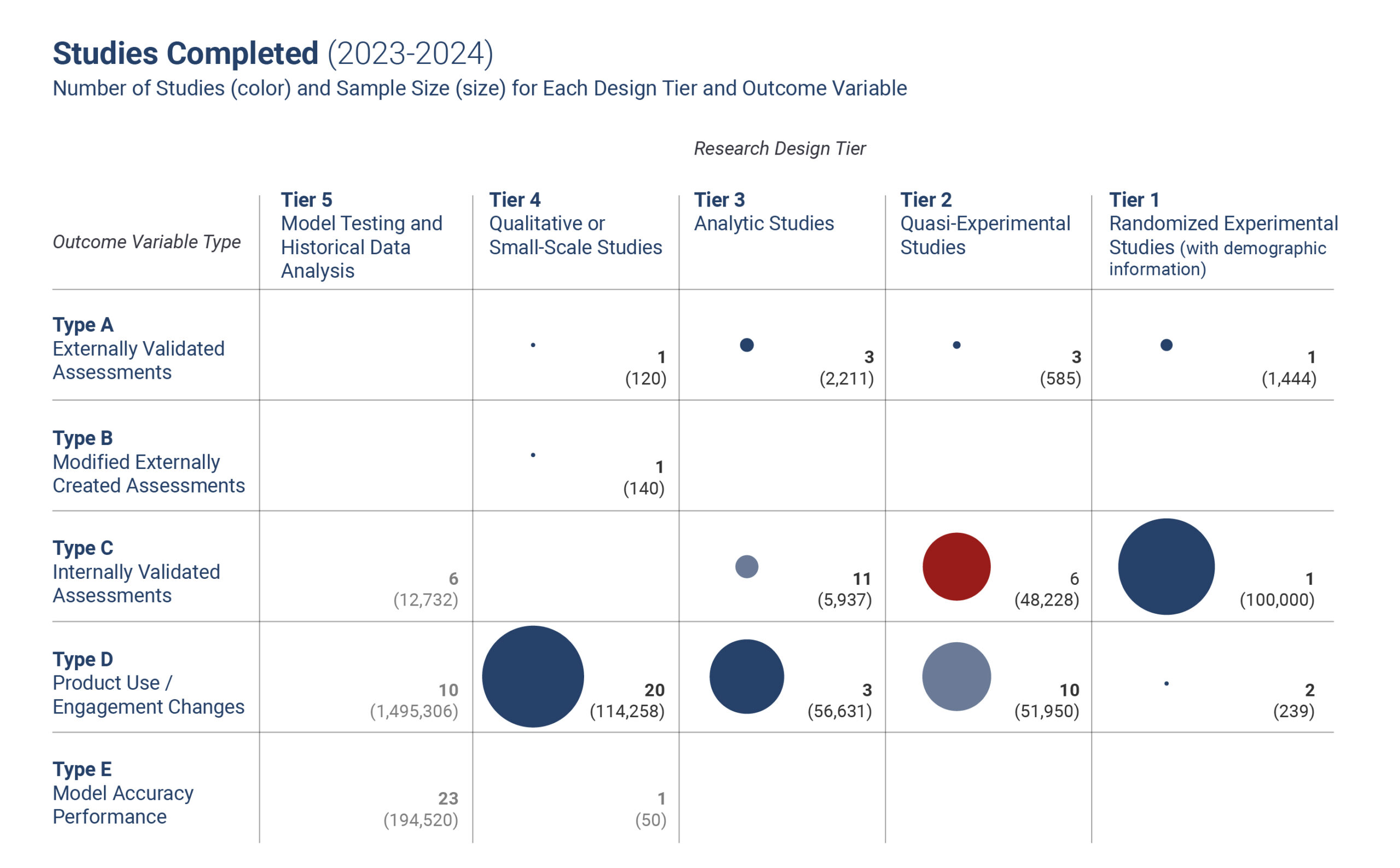
Results & Next Steps
Using these categories over the past year has enabled us to better represent the experimental activities conducted by LEVI teams and distinguish which teams are closer to readiness for an RCT-like research study from those that have additional research that needs to be conducted. This approach has also enabled us to provide more consistent (and robust) descriptions of research across the entire portfolio – while recognizing the variability between teams and projects.
This approach to classification is not complete, and we have ongoing discussions, especially around the relative value of quasi-experimental designs in large-scale field trials vs. randomized controlled trials with smaller populations under known conditions. As usual, the process of creating these categories, and refining the approach, has produced more insights than the final output, and we look forward to continuing to refine this approach with the LEVI leadership and research teams in the coming years.
By John Whitmer & Alexis Andres, Learning Data Insights


